- 特許

- 商標
- イノベーション
- ソリューション
- お問合せ
- 学ぶ・サポート
- 学ぶ・サポート
- ウェビナー&イベントオンラインまたはオンサイトのイベントにご興味がおありですか?
- 製品トレーニングお客様の成功が最優先です。クエステルのソフトウェアの使用に関するスキルを高める
- 製品ニュースソフトウェアやプラットフォームに関するニュースや進化に特化したプラットフォームです。
- クラス最高のカスタマー・エクスペリエンス当社の目標は、一貫して優れた顧客サービスを提供し、製品、サービス
- IPトレーニングIP 専門家以外の人向けに設計された魅力的な IP トレーニングで、組織全体の IP-IQ を高めます。
- ウェビナー&イベント
- Questelについて
- 学ぶ・サポート
- 学ぶ・サポート
- ウェビナー&イベントオンラインまたはオンサイトのイベントにご興味がおありですか?
- 製品トレーニングお客様の成功が最優先です。クエステルのソフトウェアの使用に関するスキルを高める
- 製品ニュースソフトウェアやプラットフォームに関するニュースや進化に特化したプラットフォームです。
- クラス最高のカスタマー・エクスペリエンス当社の目標は、一貫して優れた顧客サービスを提供し、製品、サービス
- IPトレーニングIP 専門家以外の人向けに設計された魅力的な IP トレーニングで、組織全体の IP-IQ を高めます。
- ウェビナー&イベント
- Questelについて

OBS: 単純な特許配列検索からバリアント解析まで
DNA、RNA 配列、およびタンパク質は、60 年代以降、およびそれ以前のいくつかの特許で開示されています。自然に発生する配列、改変された配列、診断に使用される配列、植物由来の配列、その他多くの種類など、さまざまな種類の生物学的材料が特許を取得できるようにするために、多くの法律が作成および修正されてきました。最近、ワクチンが話題になっていることがわかりました。RNA ワクチンなど、一部のワクチンには配列が含まれています。配列を公開している産業分野は意外に思えるかもしれませんが、食品産業や洗剤メーカーなどはその一部です。明らかに、製薬業界、バイオテクノロジー、農薬、および種子会社が大量の配列特許を生み出しています。では、なぜ特許配列検索が重要であり、他のタイプの特許検索と異なるのでしょうか?
特許配列データ
90 年代に始まり、ヒトゲノム プロジェクトでは、ゲノム配列と mRNA 配列が特許でより一般的になるようになりました。場合によっては、数百万の塩基対で構成されている可能性のある全ゲノム (細菌、真菌由来) が公開されました。民間企業は数百万の短い配列を開示し、場合によっては主張した。これはすべて、すべての特許が純粋に紙に提出されたときに起こっています。配列特許のおかげで、特許の電子出願や配列表などの補足資料がついに利用可能になりました。それ以来、配列を持つ特許の数は増加しており、中国の特許が大幅に増加したにもかかわらず、世界中で新たに公開された配列を持つ特許の数は依然として線形曲線をたどっています。
 2000 年から 2020 年までに新しく公開された配列特許の履歴トレンドが Orbit BioSequence で利用できます。
2000 年から 2020 年までに新しく公開された配列特許の履歴トレンドが Orbit BioSequence で利用できます。
歴史的な三大機関 (USPTO、EPO、WIPO) は、それぞれの配列を公開しています。 JPO、KIPO、CIPO など、その他の当局は非常に準拠しています。残念ながら、他の人はあまり体系的でなかったり、過去にとらわれたりしています。しかし、厳格に準拠している当局であっても、どの配列を開示すべきかに関する規則や法律はさまざまです。このように、シーケンス特許は、同じファミリーの USPTO または WIPO 文書と EPO 文書では異なる可能性があるため、特許のファミリー ビューを持つことを強くお勧めします。
特許配列検索が異なるのはなぜですか?
従来の IP 検索はキーワードで行われます。キーワードによる検索は不完全であるため、基本的にはキーワードの正確性の欠如によって引き起こされる痛みを軽減しようとする、特許クラス、同義語リスト、およびその他の多くの機能と組み合わせて使用されます。
生物学的配列検索は、いくつかの理由で異なります。第一に、特許が書かれている母国語から完全に独立した、DNA/RNAおよびアミノ酸配列を記述するための共通言語があります。したがって、自然言語翻訳は必要ありません。
第二に、配列は非常に長くなる可能性があるため、配列表でそれらを別々に扱うために、いくつかの出版基準が長年にわたって存在してきました.したがって、公開されたシーケンスの大部分は、電子的に簡単に処理できます。これは、画像がまだ出版物の受け入れ可能な形式である化学とは対照的です。
第 3 に、シーケンスが非常に短い場合を除き、同一であるだけでなく、類似したシーケンスを常に見つけたいと思うでしょう。小さなエラー (OCR のミス、発行者のエラー) は何らかの方法で制御できるため、これは特に重要です。対照的に、「パン イースト」というキーワードで検索すると、「ビーズ イースト」はスペル ミスであっても見つかりません。
第四に、過去 20 年ほどの間、特許で公開された配列には番号が付けられ、キーワード SEQ ID NO. によって参照されています。ほとんどの場合、たとえばヒット配列 5 が請求されているかどうかを知ることは簡単です。これは、特許請求の範囲でその番号が SEQ ID NO. として言及されているためです。 5. これはシーケンスの固有の機能であり、非常に重要な機能であり、シーケンス インスタンスを (要求された) として強調表示することができます。
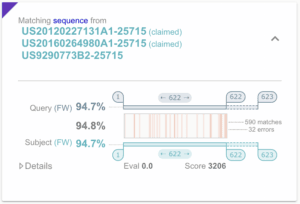
Orbit BioSequence でクレームされているかどうかに関係なく、3 つの USPTO 文書に記載されている配列にアラインされた配列。
バリアント分析は、クエリにアラインされたすべての特許配列をスタックし、各クエリ位置のグローバル ビューを提供します。つまり、クエリ シーケンスに基づいて複数のアラインメントが作成されます。データセットのクエリ、変更、およびエクスポートを行うことができます。最も重要なことは、バリエーションを調べて、たとえば、競合他社が何をしているのか、または変更されていない領域について新しい洞察を得ることができることです。

Orbit BioSequence Variant Analysis を使用した複数の位置での変化
軌道バイオシーケンス (OBS)
特許配列と非特許配列に幅広くアクセスできるOrbit BioSequence は、FTO、特許性、ビジネス インテリジェンスの検索に最適なツールです。特許データと配列を簡単に組み合わせることで、OBS は特許配列検索を純粋に配列専用の他のツールよりもはるかに簡単にします。抗体と CDR、遺伝子、プライマーをすべて使用、組み合わせ、探索できます。
詳細を知りたいですか?具体的なアドバイスやサポートについてはお問い合わせいただくか、 Orbit BioSequence による特許データの最近のウェビナー Smart & Visual Sequence Variation Explorerの録画をご覧ください。